基于Caret和RandomForest包进行随机森林分析的一般步骤 (1)


Caret构建机器学习流程的一般步骤Caret依赖trainControl函数设置交叉验证参数,train函数具体训练和评估模型。首先是选择一系列需要评估的参数和参数值的组合,然后设置重采样评估方式,......
Caret依赖trainControl函数设置交叉验证参数,train函数具体训练和评估模型。首先是选择一系列需要评估的参数和参数值的组合,然后设置重采样评估方式,循环训练模型评估结果、计算模型的平均性能,根据设定的度量值选择最好的模型参数组合,使用全部训练集和最优参数组合完成模型的最终训练。

createDataPartition是拆分数据为训练集和测试集的函数。对于分类数据,按照每个类的大小成比例拆分;如果是回归数据,则先把响应值分为n个区间,再成比例拆分。
CreatemodelwithdefaultparameterstrControl-trainControl(method="repeatedcv",number=10,repeats=3)设置随机数种子,使得结果可重复(seed)rf_default-train(x=train_data,y=train_data_group,method="rf",trControl=trControl)saveRDS(rf_default,"rda/rf_")}print(rf_default)
RandomForest59samples7070predictors2classes:'DLBCL','FL'Nopre-processingResampling:Cross-Validated(10fold,repeated3times)Summaryofsamplesizes:53,53,54,53,53,54,Resamplingresultsacrosstuningparameters:=7069.
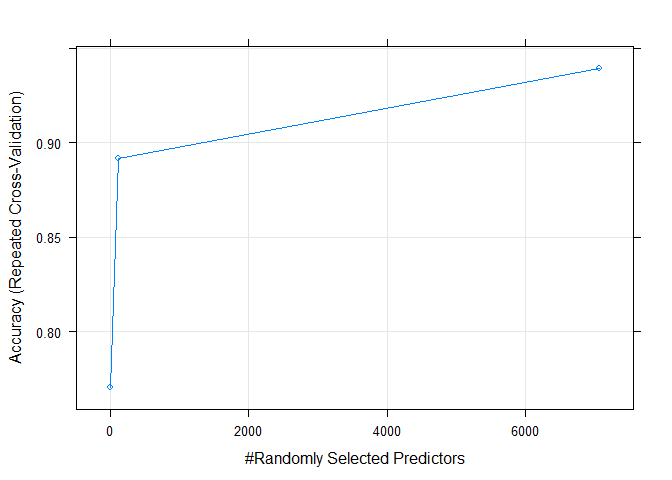
精确性随默认调参的变化
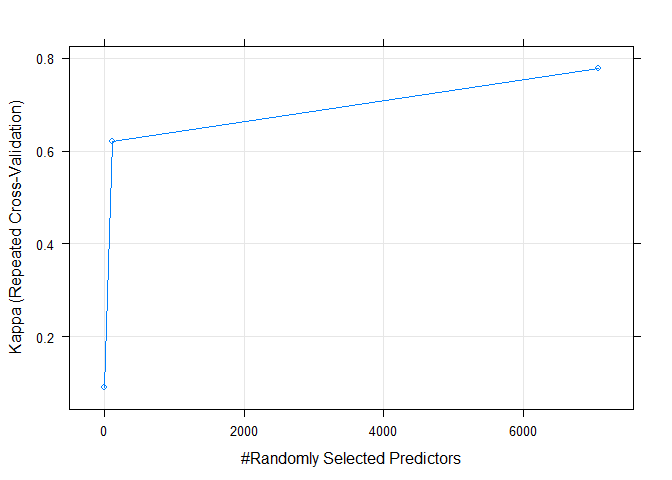
plot(rf_default)
str(rf_default)Caret比较不同算法的性能
Caret包的流程统一性在这就体现出来了,我之前没有看过ranger和parRF包,也不知道他们的具体使用。但我可以借助Caret很快地用他们构建一个初步模型,并与randomForest的结果进行比较。
RRF:RegularizedRandomForestif(('rda/RRF_')){RRF_default-readRDS("rda/RRF_")}else{(1)RRF_default-train(x=train_data,y=train_data_group,method="RRF",trControl=trControl)saveRDS(RRF_default,"rda/RRF_")}RRF_defaultRegularizedRandomForest59samples7070predictors2classes:'DLBCL','FL'Nopre-processingResampling:Cross-Validated(10fold,repeated3times)Summaryofsamplesizes:53,53,54,53,53,54,Resamplingresultsacrosstuningparameters:=118,coefReg=1andcoefImp=0.
ranger是randomforest的快速版本,特别适用于高维数据,支持分类、回归和生存分析。
rangerisafastimplementationofrandomforests(Breiman2001)orrecursivepartitioning,,regression,RandomForest(Breiman2001),survivalforestsasinRandomSurvivalForests().if(('rda/ranger_')){ranger_default-readRDS("rda/ranger_")}else{(1)ranger_default-train(x=train_data,y=train_data_group,method="ranger",trControl=trControl)saveRDS(ranger_default,"rda/ranger_")}ranger_defaultRandomForest59samples7070predictors2classes:'DLBCL','FL'Nopre-processingResampling:Cross-Validated(10fold,repeated3times)Summaryofsamplesizes:52,52,54,53,53,53,Resamplingresultsacrosstuningparameters:''washeldconstantataval=7069,splitrule==1.
parRF是并行随机森林算法。
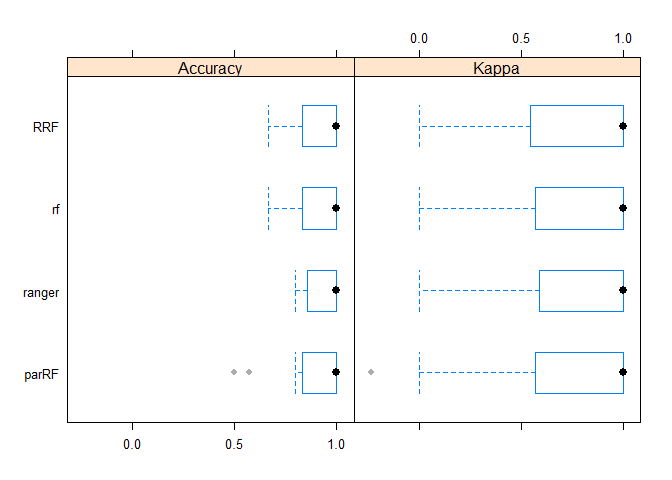
这个结果时对时错,对Kappa值很高估,还没看什么原因bwplot(resamps)
这个结果跟输出的矩阵是吻合的
dotplot(resamps)
统计检验评估模型之间差异是否显著
(resamps)summary()
Call:(object=)p-valueadjustment:bonferroniUpperdiagonal:estimatesofthedifferenceLowerdiagonal:p-valueforH0:difference=0Caret训练最终模型
if(('rda/rf_')){rf_final-readRDS("rda/rf_")}else{设置随机数种子,使得结果可重复(seed)rf_final-train(x=train_data,y=train_data_group,method="rf",??#Areaunderthecurve:0.9821ROC_(FPR=1-roc$specificities,TPR=roc$sensitivities)ROC_data-ROC_data[order(ROC_data$FPR),]p-ggplot(data=ROC_data,mapping=aes(x=FPR,y=TPR))+geom_step(color="red",size=1,direction="mid")+geom_segment(aes(x=0,x=1,y=0,y=1))+theme_classic()+xlab("Falsepositiverate")+ylab("Truepositiverate")+coord_fixed(1)+xlim(0,1)+ylim(0,1)+annotate('text',x=0.5,y=0.25,label=paste('AUC=',round(roc$auc,2)))p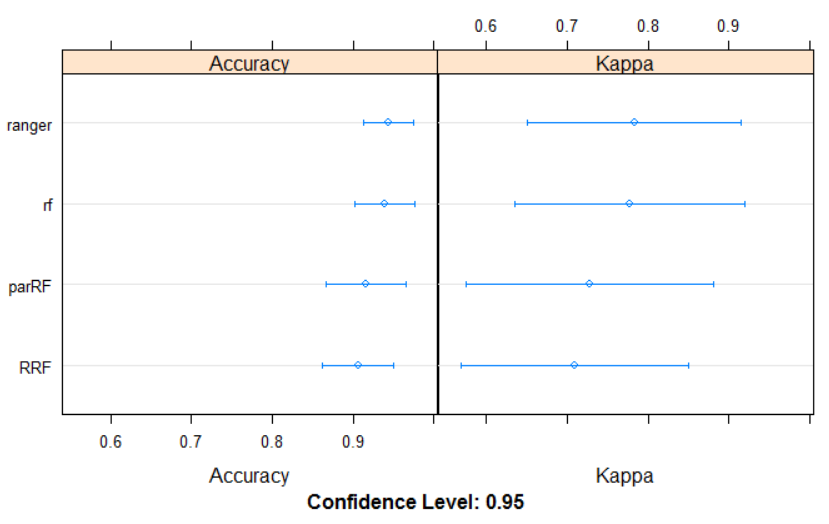
机器学习系列教程
从随机森林开始,一步步理解决策树、随机森林、ROC/AUC、数据集、交叉验证的概念和实践。
文字能说清的用文字、图片能展示的用、描述不清的用公式、公式还不清楚的写个简单代码,一步步理清各个环节和概念。
再到成熟代码应用、模型调参、模型比较、模型评估,学习整个机器学习需要用到的知识和技能。
机器学习算法-随机森林之决策树初探(1)
机器学习算法-随机森林之决策树R代码从头暴力实现(2)
机器学习算法-随机森林之决策树R代码从头暴力实现(3)
机器学习算法-随机森林之理论概述
随机森林拖了这么久,终于到实战了。先分享很多套用于机器学习的多种癌症表达数据集。
机器学习算法-随机森林初探(1)
机器学习模型评估指标-ROC曲线和AUC值
机器学习-训练集、验证集、测试集
机器学习-随机森林手动10折交叉验证
一个函数统一238个机器学习R包,这也太赞了吧
本文链接:https://wexi.porsven.com/501182600021.html