pandas如何操作Excel?还不会的,看此一篇足矣


pandas是一款基于NumPy的数据分析工具。它提供了大量的能使我们快捷处理数据的方法。常用数据类型Series:一维数组,与NumPy中的一维数组相似,和Python自身的list也相似。区别自于......
pandas是一款基于NumPy的数据分析工具。它提供了大量的能使我们快捷处理数据的方法。

Series:一维数组,与NumPy中的一维数组相似,和Python自身的list也相似。区别自于Series中的数据只能是一种数据,而list中的数据可以不一样
Time-Series:以时间为索引的Series
DataFrame:二维的表格型数据结构。经常用于处理Excel表格数据等,这也是我们本节课会重点讲的内容
Panel:三维数组(0.25版本后,统一使用xarray,不再支持Panel)
Series和DataFrame的互转利用to_frame()实现Series转DataFrame
利用squeeze()实现单列数据DataFrame转Series
s=_frame(name="列名")s

()使用pandas读取Excel表格
在pandas中,读取Excel非常简单,它只有一个方法:readExcel(),但是的参数非常多
主要常用的参数,我们先对其进行了解:
io:一般指定excel文件路径就可以了。也可以是其他Excel读取对象如ExcelFile、等
sheet_name:用于指定工作表(sheet)名称。可以是数字(工作表从0开始的索引)
header:指定作为列名的行,默认为0,即第一行为列名。如果数据不含列名,则设为None
names:指定新的列名列表。列表中元素个数和列数必须一致
index_col:指定列为索引列,默认None指的是索引为0的第一列为索引列
usecols:要解析数据的列,可以是int或者str的列表,也可以是以逗号分隔的字符串(新增功能),例如:”A:F”,表示从A列到F列,”A,C,F”表示A、C、F三列,还可以写成”A,C,F,K:Q”
dtype:各列的数据类型,例如:{‘a’:,‘b’:}
converters:用于转换各列数据的函数的字典数据,例如:{‘a’:func_1,‘b’:func_2}
importpandasaspdsheet=_excel(io="测试数据.xlsx")()

我们先来看一下取回的数据的数据类型是什么。
print(type(sheet))
class''
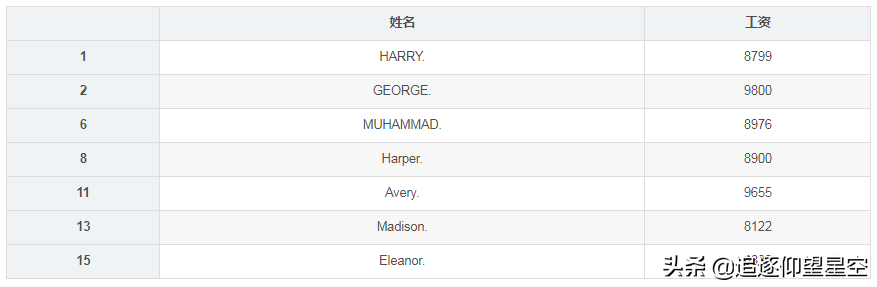
可以看到,它就是我们前面提到的DataFrame数据。,直接通过它的列名称来获取即可,比如,要获得所有的工资信息,可以如下:
print(sheet['工资'])
07653128804360053200088900976881067121196551268548158830Name:工资,dtype:int64
可以看到它的所有的数据都列出来了,并且这一列数据的数据类型是int64,即64位整型。
得到这一列数据后,我们可以对它进行处理。
foriinsheet['工资']:print(i)
7653879990030089007688671296556854812267888830
或者将它转换成列表后再处理:
salaries=list(sheet['工资'])print(salaries)
[7653,8799,9800,12880,3600,3800,8976,12000,8900,7688,6712,9655,6854,8122,6788,8830]
计算大家的平均工资:
sum=0foriinsalaries:sum+=iprint(f"总工资:{sum}")ave=sum/len(salaries)print(f"平均工资:{ave}")总工资:131057平均工资:8191.0625
importfunctoolssum=(lambdax,y:x+y,salaries)print(sum)
131057
importpandasaspdsheet=_excel(io="测试数据.xlsx",usecols=[2])sheet

或者:
importpandasaspdsheet=_excel(io="测试数据.xlsx",usecols=['工资'])sheet
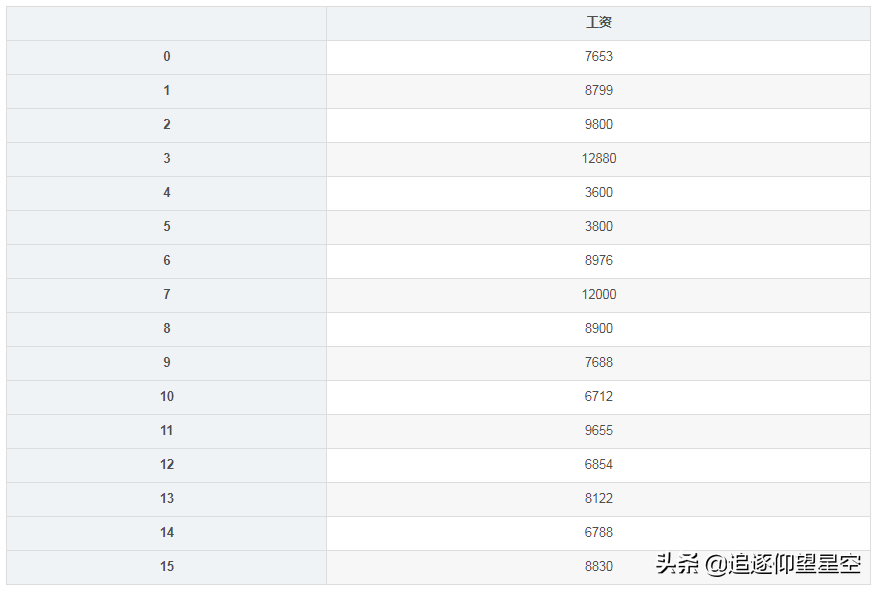
importpandasaspdsheet=_excel(io="测试数据.xlsx",names=['name','age','salary'])sheet
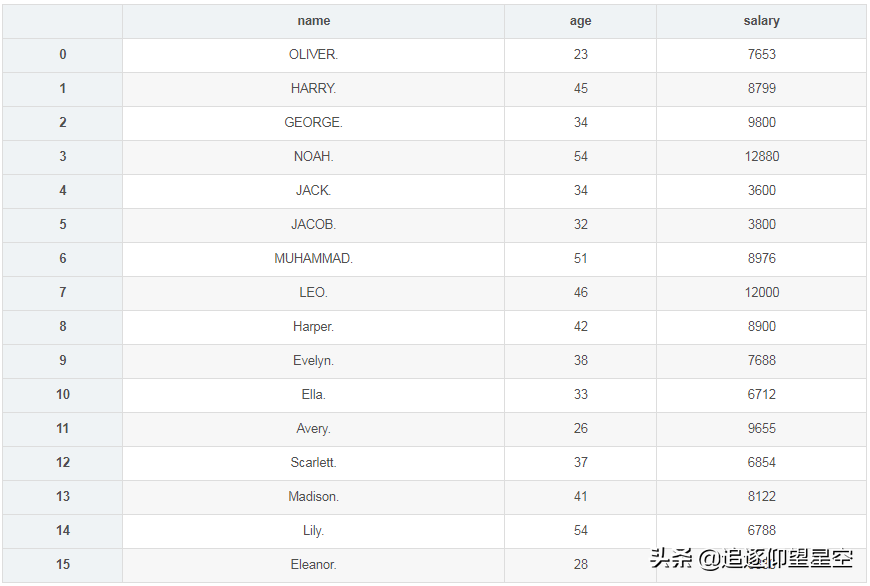
importpandasaspddefformatsalary(num):returnf"¥{format(num,',')}"sheet=_excel(io="测试数据.xlsx",usecols=['工资'],converters={'工资':formatsalary})sheet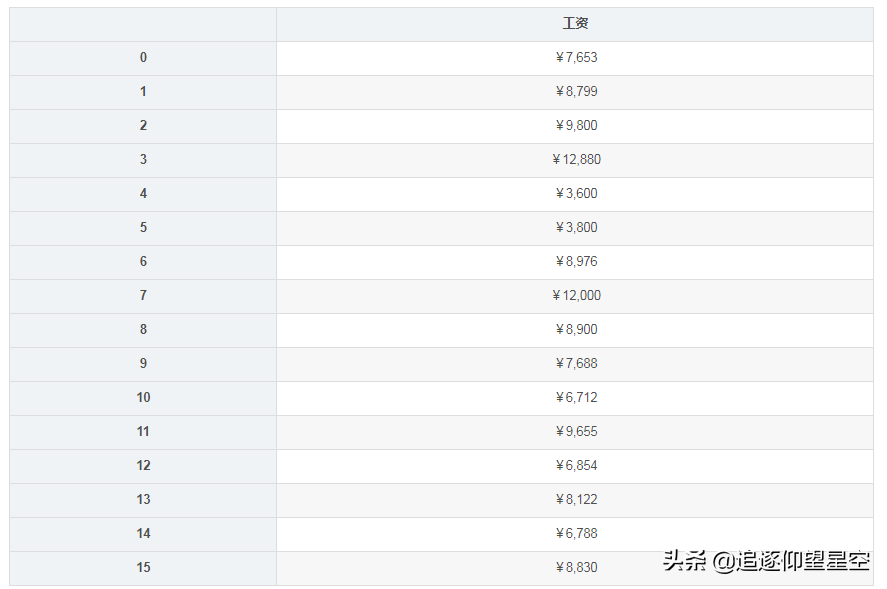
上面通过converters指定了“工资”列,使用formatsalary函数来处理,所以取出来的数据就已经处理过的了。当然,我们也可以取出来后再对其进行格式化。
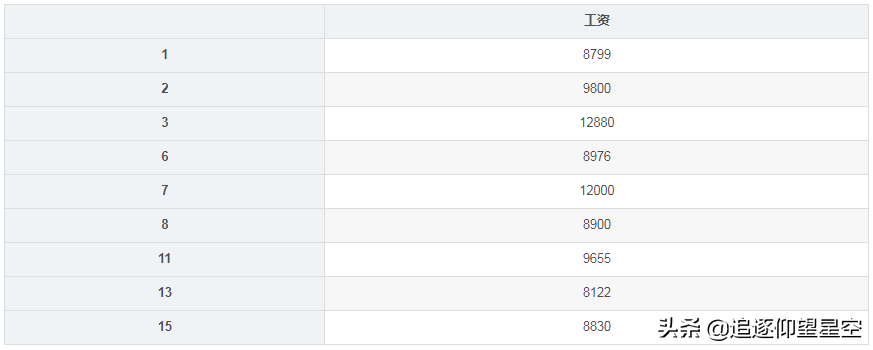
其他的参数,大家可以自己进行试验。下面我们再来看一下,假设我要取出所有大于等于8000的工资,该如何进行处理呢?我们可以使用按照条件来获取DataFrame的行数据:
importpandasaspdsheet=_excel(io="测试数据.xlsx",usecols=['工资'])high_salary=sheet[sheet['工资']=8000]high_salary
如果想取得工资大于等于8000小于等于10000的数据:
importpandasaspdsheet=_excel(io="测试数据.xlsx")high_salary=sheet[(sheet['工资']=8000)(sheet['工资']=10000)]high_salary

如果只想显示符合条件的姓名和工资,则可以通过列表的方式指定要显示的列:
importpandasaspdsheet=_excel(io="测试数据.xlsx")high_salary=sheet[(sheet['工资']=8000)(sheet['工资']=10000)][['姓名','工资']]high_salary
在上面的例子中,虽然在“测试数据.xlsx”文件中包含了两个数据表(sheet),但它只读取了第一个数据表的内容,如果我想把两个数据表数据都读取出来该怎么办呢?可以指定sheet_name参数,它接收字符串、数字、字符串或数字列表以及None。如果指定为None,则返回所有数据表数据。默认为0,即返回第一个数据表数据。
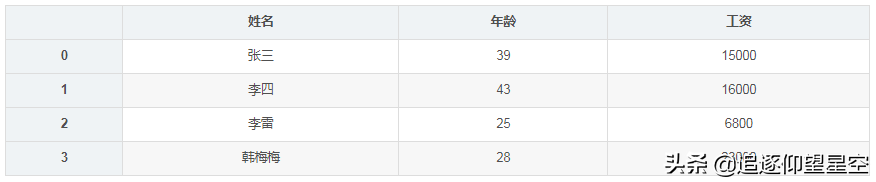
importpandasaspdsheet=_excel(io="测试数据.xlsx",sheet_name=[0,1])sheet
{0:姓名年龄工资0,1:姓名年龄工资0张三39150001李四43160002李雷2568003韩梅梅2823000}可以看到,得到了两个数据表的数据。此时要得到数据表中的数据,就需要先通过sheet[0]、sheet[1]得到第一个数据表的所有数据,再在这个数据表数据中对数据进行处理了,例如:
sheet[1]
如果用的是数据表的名字,则应该写成sheet[‘甲公司’]。
如果我们想把这两个数据表的数据合并到一起,可以使用pandas中的concat()函数:
importpandasaspdsheet=_excel(io="测试数据.xlsx",sheet_name=[1,0])st=(sheet,ignore_index=True)st
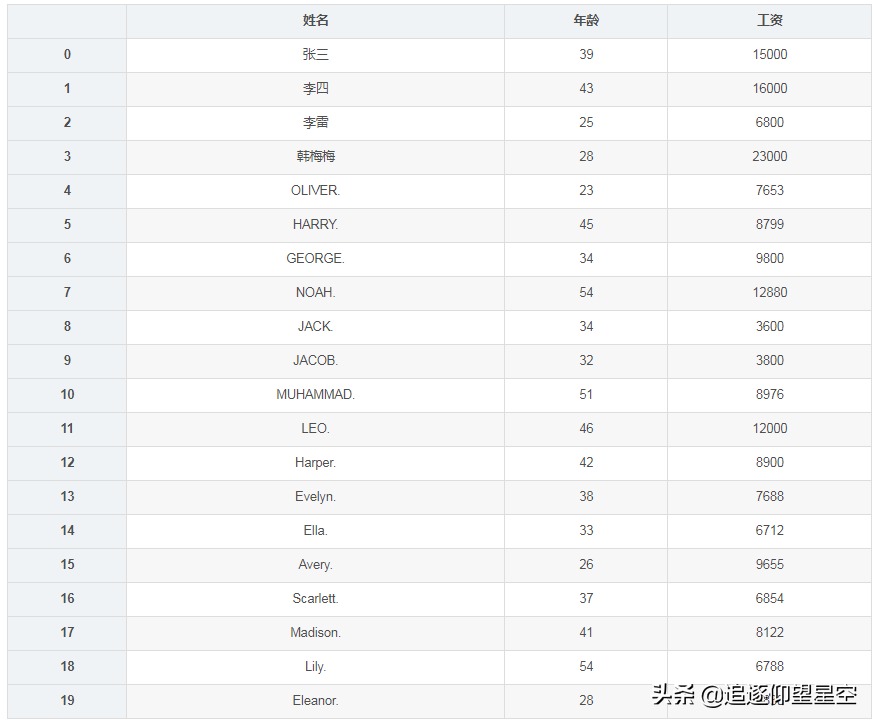
这里ignore_index的意思是忽略各自的索引,统一使用新的索引。
合并多个工作表多个EXCECL合并到一个工作表中,Python来帮你实现
@Address:"E:\Python\00数据分析\RichardFu123\五省\archive"dfs,index=[],0(path):(_csv((path,i)))print(f"正在合并{index+1}工作表")index+=1df=(dfs)_csv("数据汇总.csv",index=False)正在合并1工作表正在合并2工作表正在合并3工作表正在合并4工作表正在合并5工作表正在合并6工作表正在合并7工作表写入Excel文件
可以将DataFrame数据写入到一个新的Excel文件中,例如,我们可以将上面合并的两个Excel数据表数据,写入到新的Excel文件中:
df=(st)_excel("合并工资报表.xlsx")这里我们使用DataFrame上的to_excel()方法将数据写入到Excel文件中。它的原型是:to_excel(self,excel_writer,sheet_name=‘Sheet1’,na_rep=’’,float_format=None,columns=None,header=True,index=True,index_label=None,startrow=0,startcol=0,engine=None,merge_cells=True,encoding=None,inf_rep=‘inf’,verbose=True,freeze_panes=None),常用的参数说明:
excel_writer:需要指定一个写入的文件,可以是字符串或者ExcelWriter对象
sheet_name:写入的工作表名称,是一个字符串,默认为’Sheet1’
na_rep:当没有数据的时候,应该填入的默认值,默认为空字符串
float_format:浮点数格式,默认为None。可以按照float_format="%.2f"这样的方式指定
columns:指定写入的列名顺序,是一个列表。
header:是否有表头,默认为True,可以是布尔类型或者字符串列表。
index:是否加上行索引,默认为True。
index_label:索引标签,可以是字符串或者列表,默认为None。
startrow:插入数据的起始行,默认为0。
startcol:插入数据的其实列,默认0
engine:使用的写文件引擎,例如:‘openpyxl’、‘xlsxwriter’
当然,我们也可以不限于将一个Excel表中的数据写入到另一个Excel文件,我们自己在程序中运行得到的数据,也可以将其组织成DataFrame后,写入到Excel文件中。
importpandasaspddf=({'姓名':['李雷','韩梅梅','小明','张三','李四','王五'],'年龄':[31,22,30,49,38,33]})_excel("员工表.xlsx",sheet_name="202002入职")看看是不是写入到文件了:
f=_excel("员工表.xlsx")f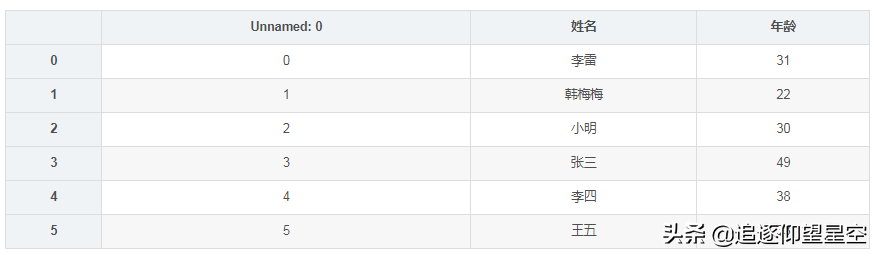
可以看到,确实已经写入进去了。
那如果要写多个数据到一个Excel文件的多个数据表(sheet)中,该怎么处理呢?此时可以使用下面的方法。
df1=({'姓名':['李雷','韩梅梅','小明','张三','李四','王五'],'年龄':[31,22,30,49,38,33]})df2=({'Names':['Andrew','Tomas','Larry','Sophie','Sally','Simone'],'Age':[42,37,39,35,29,27]})dfs={'国内员工':df1,'外籍员工':df2}writer=('',engine='xlsxwriter')forsheet_():dfs[sheet_name].to_excel(writer,sheet_name=sheet_name,index=False)()看看是不是已经写入到文件了:
sheet=_excel(io="",sheet_name=None)sheet
{'国内员工':姓名年龄0李雷311韩梅梅222小明303张三494李四385王五33,'外籍员工':NamesAge0Andrew421Tomas372Larry393Sophie354Sally295Simone27}但是仔细看的话,会发现上面的外籍员工这个数据表,字段Names和Age反了,这是因为DataFrame自动按照字母顺序给我们排序了。要避免这种情况,需要在to_excel()中加上columns来指定表头字段顺序:
df1=({'姓名':['李雷','韩梅梅','小明','张三','李四','王五'],'年龄':[31,22,30,49,38,33]})df2=({'Names':['Andrew','Tomas','Larry','Sophie','Sally','Simone'],'Age':[42,37,39,35,29,27]})dfs={'国内员工':df1,'外籍员工':df2}cols={"国内员工":['姓名','年龄'],"外籍员工":['Names','Age']}加载原有的数据到Workbookdf3=({'Names':['Judy'],'Age':[27]})('',engine='openpyxl')aswriter:=book加载原有的数据到Workbookdf4=({'Names':['Moore'],'Age':[38]})('',engine='openpyxl')aswriter:=book#让writer加入原来的3个={:}start_row=['候补员工'].max__excel(writer,sheet_name='候补员工',index=False,columns=['Names','Age'],startrow=start_row,header=False)()这里的要点是:使用startrow指定要插入数据的文字,这里还要注意我们是往某个已经存在的数据表插入数据,所以要指定正确的sheet_name,还有就是为了避免重复的表头,将header设置成False。
importpandasaspdsheet=_excel(io="",sheet_name=None)sheet
{'国内员工':姓名年龄0李雷311韩梅梅222小明303张三494李四385王五33,'外籍员工':NamesAge0Andrew421Tomas372Larry393Sophie354Sally295Simone27,'候补员工':NamesAge0Judy271Moore38}
本文链接:https://wexi.porsven.com/732182499392.html